
 James Corbett – Do you want the good news first or the bad news?
James Corbett – Do you want the good news first or the bad news?
Alright, here’s the bad news: Google is about to start ranking sites according to their conformity with mainstream opinion. Or at least that’s what the headlines would have you believe.
The usual sources in the controlled corporate media are telling you that this is a good thing and that only “Anti-science advocates are freaking out about Google truth rankings,” but if that seems like a remarkably blase attitude to take when facing the prospect of a 1984-like reality where the modern-age Ministry of Truth (Google) is going to determine the “truth” of controversial subjects and rank search results accordingly, then keep in mind that such articles are written by the likes of Joanna Rothkopf, daughter of mini-Kissinger and author of “Superclass,” David Rothkopf.
New Scientist–the website that broke the story with their article “Google wants to rank websites based on facts not links“–also framed the story, predictably enough, as “science” versus “anti-science,” starting their article by lamenting the fact that “Anti-vaccination websites make the front page of Google, and fact-free ‘news’ stories spread like wildfire.” The article rejoices in the fact that the good chaps at Google have come up with a bulletproof answer to this mess: “rank websites according to their truthfulness.”
The slightly good news is that, ironically enough, the New Scientist article seems to be a perfect example of a fact-free story spreading around the internet like wildfire. While the story does link to a research paper from a Google research team that outlines a “novel multi-layer probabilistic model” for assigning a “trustworthiness score” to web pages, it neglects to mention that the idea is still very much a theoretical work-in-progress at the moment and is nowhere near ready to be launched. If you have a fetish for multivariate equations, dynamically selected granularity, and line graphs comparing calibration curves for various data analysis methods, have at it! For the rest of us who are not fluent in boffin-speak, the gist of it is this:
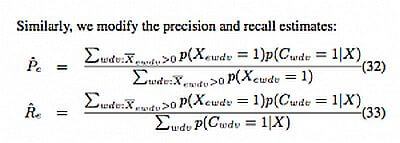
First, a page is harvested for its “knowledge triples.” These are connected triplets of information consisting of a subject, predicate and object. The paper itself helpfully provides the example: Obama – Nationality – USA. A “false value” (again according to the paper itself) would be Obama – Nationality – Kenya. These knowledge triples are assessed for their (Google-determined) accuracy and the page is assigned a KBT (Knowledge-Based Trust) score, which Google could use in place of (or perhaps in some combination with) the traditional PageRank score to determine how high in the search results the web page should place. Continue reading